

Wait! Have you read Part I yet? Check it out, then come on back.
Putting text embeddings to work
Using the updated text embeddings endpoint in Babel Street Analytics, you’ll notice significant accuracy improvements on longer strings of text, both sentences and documents. We’ve also incorporated text embeddings into some of our higher level natural language processing tasks, including name matching, categorization, and relationship extraction. In this post we discuss some of the nuances behind text embeddings, look at a real world use case, and provide some resources for further exploration.
Different tasks, different text embeddings
Different natural language processing tasks require different vector representations. For part-of-speech tagging, you probably want your word embeddings to prioritize morphological or syntactic associations between words: nouns with nouns, adjectives with adjectives etc. However, for a categorization task, you might want your embeddings to prioritize semantic similarity: “kangaroo” with “marsupial,” “voted” with “election.” Semantic text embedding models can also help train statistical classifiers, particularly neural networks. After assigning vectors to a collection of documents, each vector is labeled with a category. With this training data prepared, you can train a neural network to predict the category of a new document based on its vector. Our text embeddings are particularly helpful for semantic tasks like document categorization, clustering, and similarity assessment.
Comparing vector representations
The classic use case for text embeddings is document similarity assessment. When calculated correctly, text vectors with close proximity indicate similar document content. However, how do you know that two vectors are similar when you’re working in several hundred dimensions? It depends, but suffice to say that for our models, we endorse the cosine method.
In addition to categorization, we also use text embeddings in our cross-lingual name matching software. Matching names is a challenging problem, especially when you start dealing with locations and organizations. Take the “College of Massachusetts.” Massachusetts is a traditional name, safe to transliterate for matching in other languages. Transliteration, the phonetic or orthographic conversion of a word from one language to another, deals with sounds, not meaning. For example, the Japanese (phonetic) transliteration of “Massachusetts” is マサチューセツ or “Masachuuusetsu.” “College” however is more complicated. As a standard dictionary word, it should be matched by translation, or conversion based on meaning. The Japanese word for university is 大学 (pronounced daigaku), thus the translation of the complete school name should be “Masachuusetsu Daigaku”. Our name matching software knows that when it encounters a dictionary word, it should use text embeddings to rank the similarity of potential name matches in the target language, ensuring that our users find the information they need.
Next steps
Want to explore more? We’ve got resources. If you’re looking to create your own document similarity analyzer, we have some some sample python code to get you started. We’ve also created a new Python script that allows you to visualize Babel Street Analytics text embeddings of the BBC News Corpus in Google’s TensorFlow projector. The script parses the raw text files into a list of documents. Each document consists of three fields: category, headline, and content. The script then creates two files which can be imported into the TensorFlow project:
- embeddings.tsv: a .tsv file with one text vector for each document
- metadata.tsv: another .tsv file containing the the metadata (category and headline) for each document
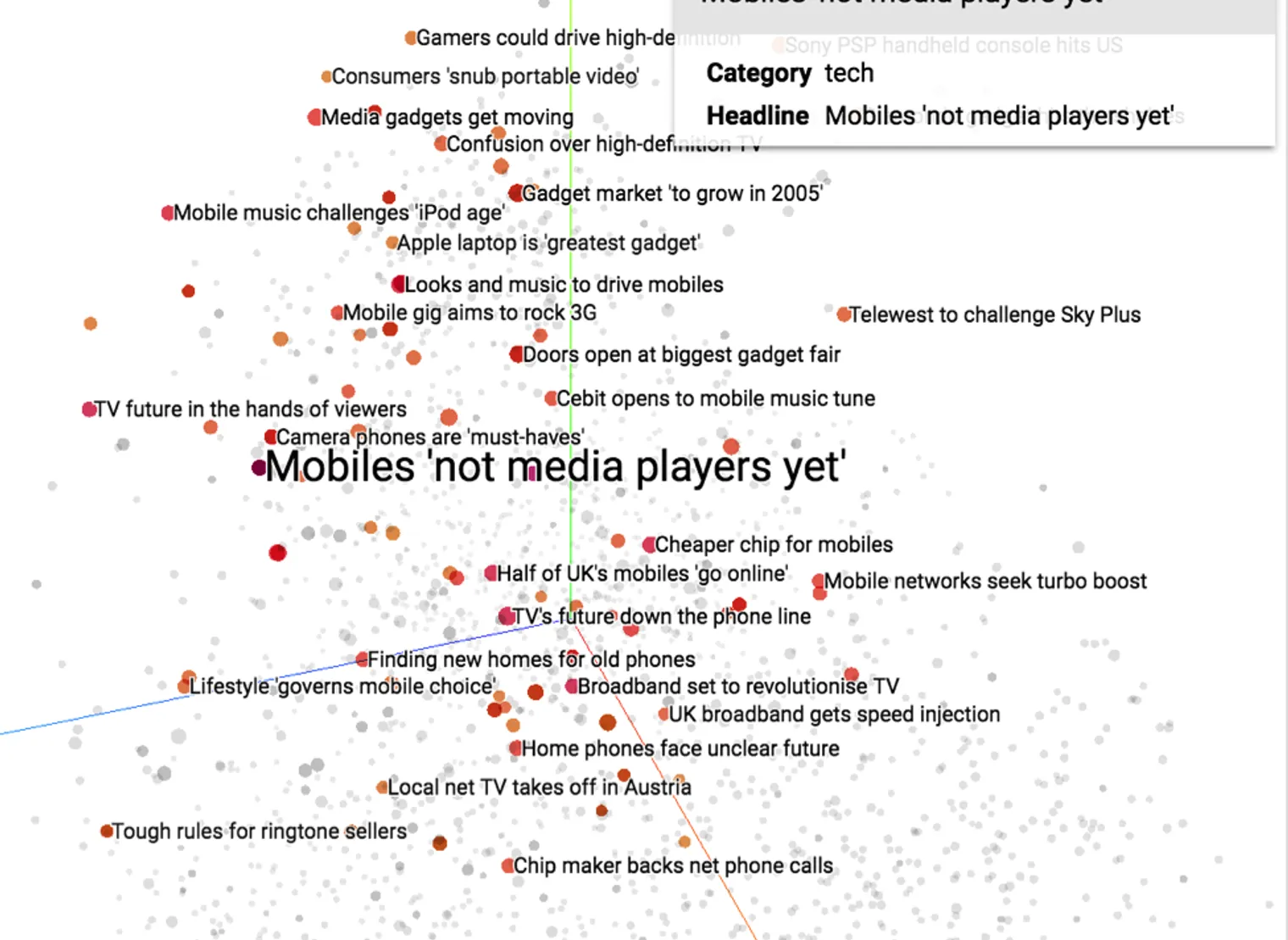
We’ve gone ahead and loaded the data into the TensorFlow projector, and the results are pretty darn cool:

In this screenshot, we’ve color coded the vectors by category, and you can see that they are nicely separated into discrete areas of the projection. You can use the mouse tools to rotate, zoom, and filter the visualization. Click on an individual embedding to isolate the closest related articles. In the screenshot below we’ve selected the embedding for an article entitled “Mobiles ‘not media players yet.’” Notice that the nearby vectors are primarily also in the “tech” category and focus on mobile phones.

Keep in mind that the vector clustering is based on the body of the articles, not their headlines, but you can still get a good sense of how our text embeddings map related content in vector space through this projection.
Find out how to transform your data into actionable insights.
Request a DemoStay Informed
Sign up to receive the latest intel, news and updates from Babel Street.







