
Babel Street Match
Deeper Insights.
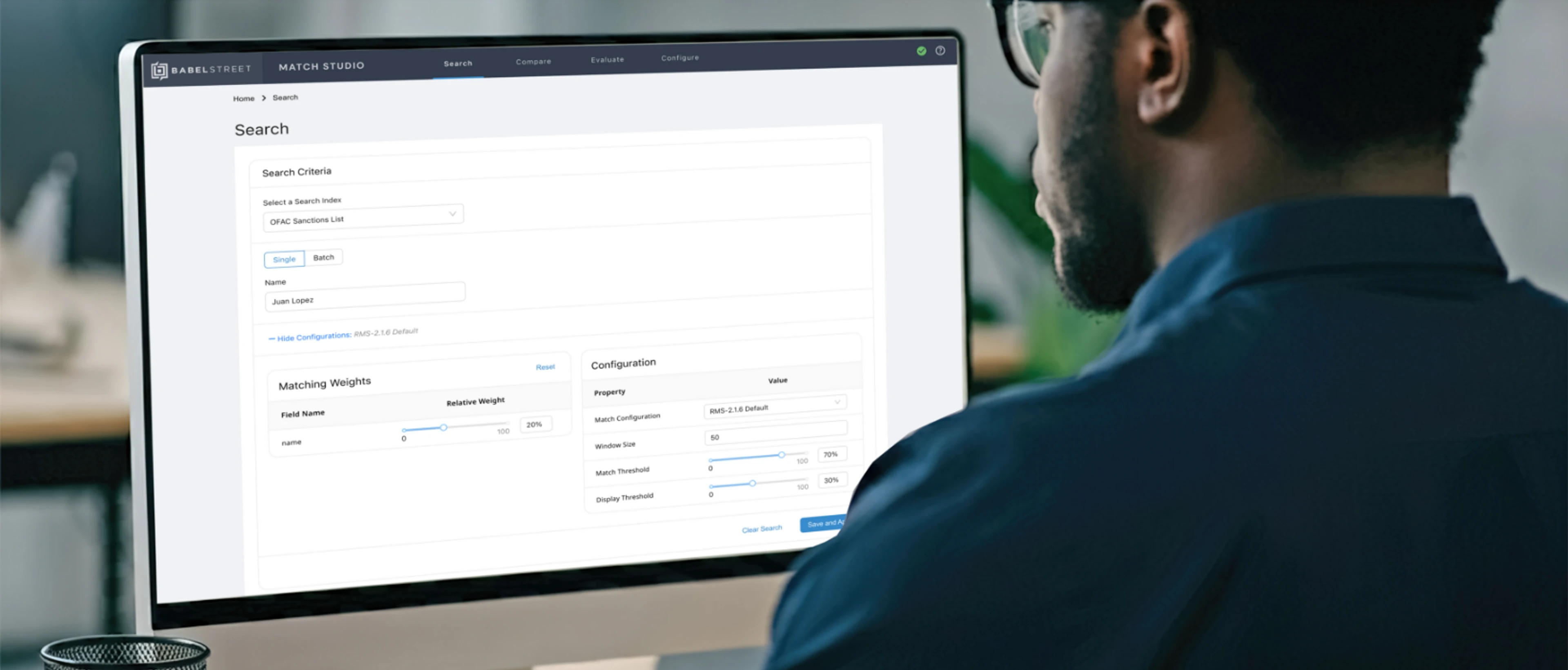
AI-powered identity matching that accurately links names, addresses, and dates across languages — reducing false positives and enabling fast, explainable decisions in high-risk environments.
Unlock the power of global name matching

Two-Pass AI Matching
Quickly shortlists Match candidates, then evaluates and scores the best matches

Fewer False Positives
Use Match scores to reduce manual checking of false positives and automate processes

Real-Time, Scalable
Get unlimited scalability with lightning-fast results, even over massive data sets

Cross-language Mastery
Screen across different scripts and languages with numerous linguistic, cultural, and contextual factors

More Than Names
Use all available identifying data to compare names, addresses, and dates

Explainable and Tunable
Configure Match parameters with explanation of how Match calculates scores
Learn More About Identity Risk Intelligence Solutions
Product Features
Purpose-built for matching
Core matching capabilities
- Multi-field matching — Go beyond names to analyze and match addresses, dates, and organizational identifiers.
- Language mastery — Leverage Match’s proven cross-lingual and cross-script expertise to match data in more than 24 languages and scripts, including Arabic, Chinese, Japanese, Korean, Russian, Spanish, and Urdu.
- Transliteration and variant handling — Match manages transliteration, spelling variations, and cultural nuances for highly accurate matching.
- Contextual and semantic intelligence — Incorporate contextual cues, including temporal data, to improve match precision and reduce false positives.
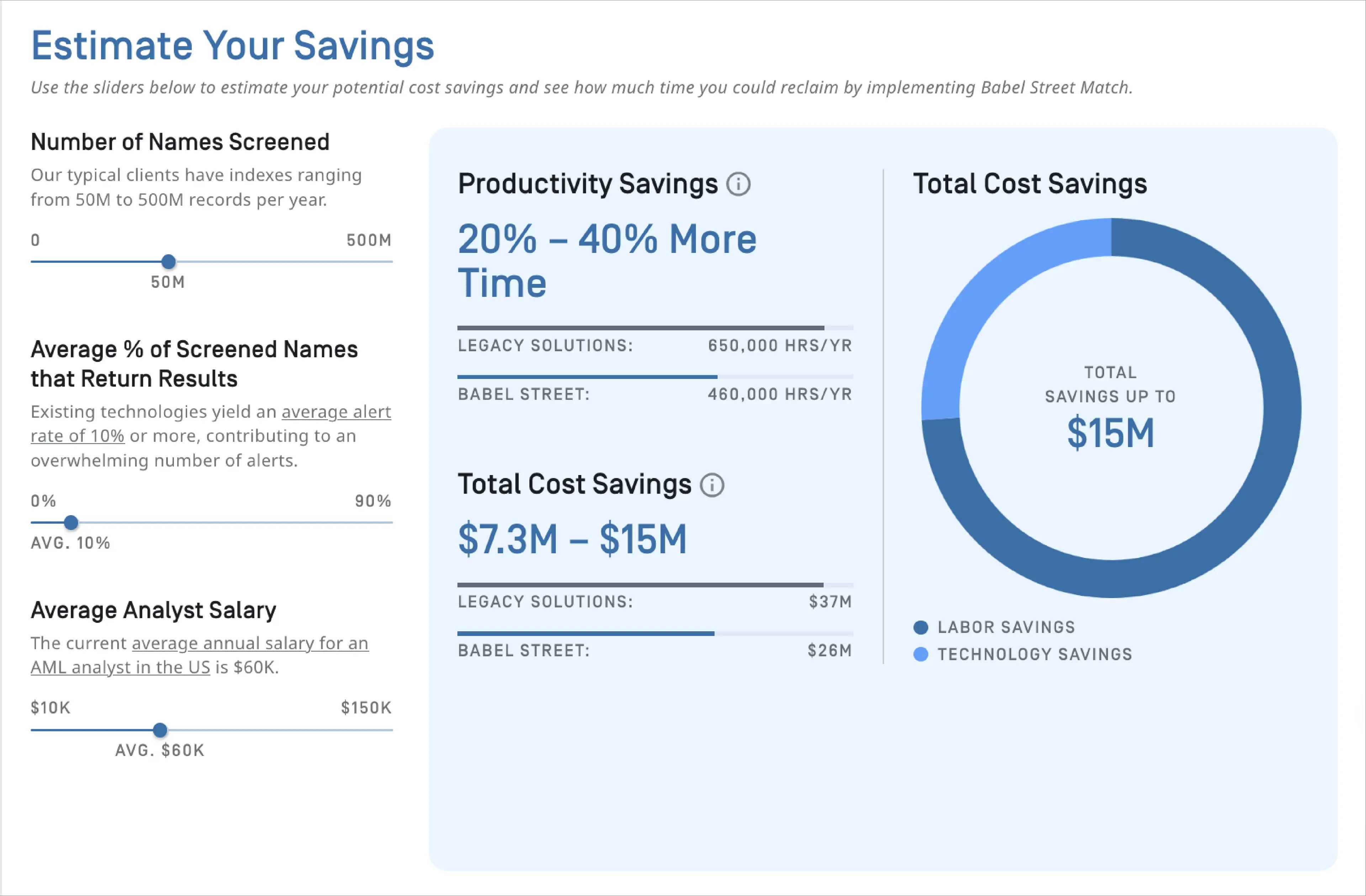
How much can you save with smarter screening?
If you’re ready to reduce risk, improve compliance, and boost productivity, view your potential cost and productivity savings with the Match ROI Calculator.

Ready to Buy?
Get Babel Street Match Plugins for Amazon OpenSearch and Elasticsearch through the AWS Marketplace.
Learn more about Babel Street Match

Data Sheet
Babel Street Match
Benefits and features of Babel Street Match for intelligent name, address, and date matching.

White Paper
Understanding Babel Street Match
A detailed, technical look at the various ways Babel Street Match handles names, weights scores, and supports multiple languages.

White Paper
Understanding Match Scoring in Babel Street Match
A detailed, technical look at how Babel Street Match scores name matches in an explainable and transparent manner.

eBook
The Complete Guide to Name Matching
The concepts around name matching, including what it is, how it’s used, and why standard search is inadequate when it comes to names.
Try it yourself or speak with an expert
Frequently Asked Questions
What is name matching?
Name matching is the process of determining whether two name records refer to the same person, organization, or entity, even when spellings, formats, or languages differ. It accounts for variations like nicknames, initials, transliteration, and typos. Modern name matching uses AI or linguistic rules to handle these inconsistencies accurately. Strong name matching is essential wherever identity clarity is required.
Why is name matching important for compliance and risk teams?
Compliance and risk teams rely on name matching to accurately screen individuals against watchlists, sanctions lists, and internal records. Even small spelling differences can cause missed matches or false positives, which create regulatory and operational risk. Effective name matching reduces manual review and improves decision confidence. It also supports faster onboarding and more reliable risk assessments.
What are the most common reasons name matching fails?
Name matching often fails due to misspellings, inconsistent formatting, nicknames, and cultural naming differences. Variations introduced by translations or transliterations also cause mismatches. Incomplete or outdated data can further reduce accuracy. Traditional keyword-based or exact match systems struggle with these cases, creating false positives and negatives.
What’s the difference between name matching and identity verification?
Name matching compares names across datasets to see if they likely refer to the same entity, while identity verification confirms a person’s identity using documents, biometrics, or authoritative sources. Name matching helps identify potential matches, but identity verification validates authenticity. Both processes are often used together in risk and compliance workflows. Name matching is the first step, and identity verification provides final confirmation.
Where is name matching used (KYC, onboarding, investigations, fraud, etc.)?
Name matching is used across KYC, AML screening, customer onboarding, fraud detection, and identity resolution. Investigators use it to connect individuals across multilingual or inconsistent datasets. Financial institutions and government agencies rely on it to ensure accurate screening and reduce compliance risk. Any workflow that depends on verifying or linking identities benefits from strong name matching capabilities.
Why is accurate name matching important?
Matching names across diverse, multilingual sources in data-intensive environments is complex. Failures in name matching — especially in critical scenarios like border screening, counterterrorism, healthcare, and financial compliance — can have severe consequences.
Can’t I just use a search engine to match names?
You can, but we don’t recommend it. Regular search engines aren’t built for the complexities of name matching. Returning only exact or near-exact matches, search platforms inevitably miss variations like nicknames and initials, and they can’t account for misspellings. Unlike search engines, Babel Street understands how names vary across languages, cultures, and ethnicities, and can consider text irregularities like out-of-order names.
What is the difference between exact, fuzzy, and phonetic name matching?
Exact name matching requires identical spelling and formatting, making it useful for clean, structured datasets. Fuzzy matching compares similarity scores between names to catch misspellings, transpositions, and variations. Phonetic matching identifies names that sound alike despite different spellings. Most modern systems combine all three approaches for higher accuracy.
How does name matching handle misspellings, aliases, and nicknames?
Name matching systems use similarity scoring, linguistic rules, and alias dictionaries to connect variations of the same name. Fuzzy algorithms detect common spelling errors, while nickname and alias mappings link informal versions to formal names. Advanced models also weigh supporting information like dates or addresses to improve match confidence. This helps reduce both missed matches and false positives.
How do name matching systems work across different languages and scripts?
Multilingual name matching relies on transliteration, script normalization, and culturally informed rules for how names are formed. AI-based systems learn patterns across languages, including ordering differences, compound names, and character variations. Some solutions also recognize when a name is translated rather than transliterated. This allows for more accurate cross-language comparisons.
What data sources are typically used for name matching (watchlists, internal records, OSINT, etc.)?
Name matching is applied to watchlists, sanctions lists, customer databases, HR systems, and case files. It’s also used with OSINT sources like news articles, public records, and social media. Combining multiple sources produces a more complete identity profile. This strengthens screening, investigation, and risk assessment workflows.
How can organizations reduce false positives in name matching?
Organizations can reduce false positives by using fuzzy matching tuned to their risk tolerance, instead of relying on rigid exact matches. Adding context — such as date of birth, address, or organizational affiliation — helps distinguish between similar names. Multilingual capabilities and culturally aware rules also improve precision. Regular tuning and testing of match thresholds keep accuracy high as data changes.
What capabilities should we look for in a name matching solution (accuracy, multilingual support, audit trails, etc.)?
An enterprise-ready name matching solution should offer high accuracy, fuzzy and phonetic matching, and deep multilingual capabilities across non-Latin scripts. It should provide transparent, explainable match scores to satisfy regulatory requirements and streamline investigations. Look for scalability, configurability, and support for complex variations in names, addresses, and dates to minimize false positives and reduce analyst workload.
Can’t a search engine do match scoring?
Many search engines use complicated ranking functions to estimate the data’s alignment to a given query. Their results are often based on factors such as how often, or how infrequently, a search term appears in a document or set of documents. The search engine’s match score is a calculation based on those frequencies. Unfortunately, that’s not optimal for name matching because, while it gives users an idea of how often search terms appear, it does not clearly indicate how closely search terms match.
What are the best name matching tools for enterprise screening and investigations?
The best enterprise tools combine high accuracy, multilingual support, explainability, and the ability to handle messy, high-volume identity data. Babel Street stands out because it delivers fast, AI-driven fuzzy name, address, and date matching across 20+ languages with mission-grade precision. It is trusted in environments like border security and intelligence screening, where even a single missed match can introduce significant risk.
What is Babel Street Match?
Babel Street Match is an AI-powered solution for organizations whose risk and identity operations depend on correctly matching names. With advanced algorithms to accurately match entities across multiple languages and scripts, Match intelligently reduces false positives and negatives of people, organizations, addresses, and dates.
How does Babel Street support name matching at scale?
Babel Street is built for high-volume, high-velocity environments, delivering consistent performance even when screening millions of records. Its two-pass AI approach ensures both speed and precision, reducing false positives and negatives across large datasets. The lightweight footprint allows deployment in distributed, edge, or portable environments without sacrificing accuracy.
How does two-pass matching work?
The first pass compares a query name to database entries, such as a watchlist, to quickly identify potential match candidates. This high-recall operation narrows the list of names that go to the more intensive second pass while also ensuring fewer names are missed.
The high-precision second pass examines the shortlist from the first pass and assigns an intuitive score to reflect the confidence of the match. Based on the score, matches can be ranked from most to least likely.
How does Babel Street calculate match scores?
As each candidate/query pair is analyzed, Babel Street’s AI adjusts the score for various types of matches. Our algorithms have been carefully curated and calibrated by our engineers to optimize how each factor affects the final score calculation. Configurations can also be set by the user to accommodate the characteristics of their data and desired goals. A final score is produced based on the weights assigned to various match phenomena. Scores are presented on a scale of 0 (no match) to 1 (exact match) and are also represented as intuitive percentages.
Can name matching thresholds be tuned to balance risk and operational workload?
Yes, Babel Street provides configurable match parameters, allowing organizations to adjust precision, recall, and field weighting to match their data quality and risk tolerance. Users can modify thresholds in real time and immediately see how those changes affect match behavior. This tuning helps reduce unnecessary manual reviews while ensuring high-risk cases are still escalated appropriately.
How does name matching integrate with KYC/AML, case management, or investigative workflows?
Babel Street integrates via API to enhance existing screening systems by post-processing results, reducing false positives, and improving identity clarity. It supports watchlist screening, ID verification, transaction processing, and case investigation through explainable match scores that regulators can audit. This makes it easy to embed high-precision identity matching into compliance, onboarding, or investigative pipelines without rebuilding infrastructure.